Un segnale acustico, è dato dal movimento repentino delle corde vocali che provocano delle brusche variazioni della pressione dell’aria circostante a frequenze che vanno dai 20Hz ai 4000Hz (varia da individuo ad individuo). Tale segnale, se captato da un microfono, provoca la variazione nel tempo dell’ampiezza di un segnale elettrico. Talesegnale elettrico, che varia nel tempo, dà luogo al segnale nel dominio del tempo. Nel caso del parlato, una prima operazione da effettuare, è quella del filtraggio con un filtro passa banda o passa basso, al fine di elidere i suoni ambientali che non fanno parte dello spettro del parlato umano.
Nella disciplina dell’analisi dei suoni, il segnale, viene suddiviso in frame, ovvero porzioni di forma d’onda nel tempo. Assumendo che il segnale vari lentamente nel tempo, si può dire che, la scelta di un’opportuno frame di dimensione piccola, può comportare la possibilità di prelevare una unità di informazione, ovvero un’unità di suono. Nel parlato, tale valore è pari a 10ms, ovvero entro 10 ms, un essere umano può al massimo pronunciare un unico suono. Ciò significa che, per poter analizzare i suoni, ci interessa prelevare delle unità di informazione, ciascuna contenuta entro 10ms.
All’interno di un frame, si effettua un campionamento; infatti, è vero che, dentro un frame vi è un’unità di informazione, per cui basterebbe entro 10 ms prelevare un ampiezza, tanto il suono è uguale entro 10 ms, ma non ci si limita a ciò, si prende un vettore di parametri calcolati opportunamente sulla base del segnale contenuto entro il frame. Per potere ottenere il frame, si prende una forma d’onda quadrata di durata 10ms e si sposta nel tempo tale finestra (window). La window però non si sceglie quasi mai quadrata, ma smussata, in maniera tale da pesare maggiormente le caratteristiche della forma d’onda vicino al centro del frame, infatti si utilizza spesso la cosiddetta finestra di hamming, che ha la forma di una “piovra”.

trasformazione anche non lineare pesata dalla finestra w(n). Tale finestra può
essere la finestra di hamming (si parla anche di filtro FIR a risposta finita), che ci permette di ridurre il frame rate risparmiando i calcoli, oppure un filtro IIR (a risposta infinita):


O meglio la short-time average magnitude, questo perché, la prima, ha il difetto di essere sensibile a grandi variazioni del segnale, essendo i campioni elevati al quadrato. Ricordo che s(i) trattasi dell’ampiezza del segnale nel punto i interno al frame che contiene N campioni. L’energia è importante nelle applicazioni vocali, in quanto l’energia varia molto come ampiezza nel tempo nel caso di suoni vocalizzati e non, come pure tra fonemi diversi; per cui viene permessa la segmentazione del parlato nei sistemi automatici di riconoscimento vocale, aiutando a determinare l’inizio e la fine delle parole isolate (ad esempio nel gms, se riesco a fare questo, allora evito di trasmettere le pause). Per avere informazioni sul contenuto spettrale della voce, si utilizza la trasformata di Fourier; però il alcuni casi, è sufficiente il ZCR (Zero Crossing Rate) per avere informazioni sul contenuto spettrale con richieste computazionali molto basse. Rappresenta il numero di volte per le quali il segnale passa per lo zero (o cambia segno) tra due campioni successivi. E’ possibile ricavare per segnali a banda stretta, la frequenza fondamentale F0 in questo modo:
L’energia è importante nelle applicazioni vocali, in quanto l’energia varia molto come ampiezza nel tempo nel caso di suoni vocalizzati e non, come pure tra fonemi diversi; per cui viene permessa la segmentazione del parlato nei sistemi automatici di riconoscimento vocale, aiutando a determinare l’inizio e la fine delle parole isolate (ad esempio nel gms, se riesco a fare questo, allora evito di trasmettere le pause). Per avere informazioni sul contenuto spettrale della voce, si utilizza la trasformata di Fourier; però il alcuni casi, è sufficiente il ZCR (Zero Crossing Rate) per avere informazioni sul contenuto spettrale con richieste computazionali molto basse. Rappresenta il numero di volte per le quali il segnale passa per lo zero (o cambia segno) tra due campioni successivi. E’ possibile ricavare per segnali a banda stretta, la frequenza fondamentale F0 in questo modo:
 Fs è la frequenza di campionamento del segnale e ZCR è espressa in zero crossing per campione. E’ possibile ottenere un valore di energia. Infatti, matematicamente, la ZCR equivale alla Q(n), per cui se sostituisco al posto del vettore T
Fs è la frequenza di campionamento del segnale e ZCR è espressa in zero crossing per campione. E’ possibile ottenere un valore di energia. Infatti, matematicamente, la ZCR equivale alla Q(n), per cui se sostituisco al posto del vettore T  … e scalo w(n) di un fattore 1/N, ottengo la seguente formula:
… e scalo w(n) di un fattore 1/N, ottengo la seguente formula:
 La ZCR ci aiuta a determinare segnali vocalizzati o meno. Infatti il modello vocale suggerisce che, al di sotto dei 3khz è concentrata l’energia della componente vocalizzata, mentre a frequenze più elevate abbiamo l’energia delle componenti non vocalizzate (unvoiced speed). Abbinando un analisi ZCR con la short-time average Energy, riesco ad individuare con precisione inizio e fine delle parole.Un’altra caratteristica del suono, è la short time autocorrelation, che è pari all’antitrasformata di
La ZCR ci aiuta a determinare segnali vocalizzati o meno. Infatti il modello vocale suggerisce che, al di sotto dei 3khz è concentrata l’energia della componente vocalizzata, mentre a frequenze più elevate abbiamo l’energia delle componenti non vocalizzate (unvoiced speed). Abbinando un analisi ZCR con la short-time average Energy, riesco ad individuare con precisione inizio e fine delle parole.Un’altra caratteristica del suono, è la short time autocorrelation, che è pari all’antitrasformata di  Fourier della densità spettrale di energia. In un certo senso l’autocorrelazione và a misurare la somiglianza tra un segnale ed il suo traslato (la formulaprecedente si riferisce ad un segnale discreto). Conserva le armoniche del segnale, l’ampiezza delle formanti e la loro frequenza. E’ inoltre caratterizzato da alcune caratteristiche importanti:
Fourier della densità spettrale di energia. In un certo senso l’autocorrelazione và a misurare la somiglianza tra un segnale ed il suo traslato (la formulaprecedente si riferisce ad un segnale discreto). Conserva le armoniche del segnale, l’ampiezza delle formanti e la loro frequenza. E’ inoltre caratterizzato da alcune caratteristiche importanti:

È ottenuta filtrando il segnale con delle finestre temporali. Perché è importante quest’ultima?Perché trova applicazione nell’estrazione dei pitch e nella discriminazione tra suono vocalizzato e non. Un’ulteriore alternativa a quest’ultima è la short time average magnitude difference function; Prendendo w(n) rettangolare di durata N, avrò:
Prendendo w(n) rettangolare di durata N, avrò:
Perché andare a ricercare la frequenza fondamentale? La frequenza fondamentale viene detta anche pitch e rappresenta per quanto concerne l’ambito del vocale, la frequenza fondamentale della vibrazione delle corde vocali. Posso utilizzare la short-time autocorrelation function per risalire a tale frequenza: Con Fs che è la frequenza di campionamento, kM è il campione m-simo a cui si rileva il primo massimo dopo quello per K=0. Quest’operazione viene effettuata dal cosiddetto stimatore di pitch che in genere attua 3 fasi:
Con Fs che è la frequenza di campionamento, kM è il campione m-simo a cui si rileva il primo massimo dopo quello per K=0. Quest’operazione viene effettuata dal cosiddetto stimatore di pitch che in genere attua 3 fasi:
 Dove con Br si indicano le componenti spettrali appartenenti al filtro r-esimo ed N la dimensione della FFT. Quando parliamo di spettrogramma, in realtà stiamo trattando una rappresentazione in tre dimensioni. Se noi, di un segnale nel tempo facciamo la FFT, per ogni frame, allora possiamo creare una rappresentazione in cui, nelle ascisse porremo il tempo, nelle ordinate le frequenze. Preso un tempo ti nelle ascisse, e tracciando una riga verticale, su tale riga, potremo individuare varie zone di colore più o meno scuro. Se una parte è scura, significa che avrò molta energia per la frequenza che trovo nell’ordinata. In sostanza lo spettrogramma è una registrazione dell’andamento dell’energia dei vari frame, visualizzata per frequenza. Ovvero mi dice che, ad esempio, nel frame che incapsula il tempo ti, l’energia è molto più concentrata per una frequenza che non per l’altra. Proprio perché è riferita ai frames, si noti come lo spettrogramma ha un’andamento a striscie verticali. Avere più energia per una data frequenza, significa che nei momenti in cui il parlato aveva quella data frequenza, l’ampiezza del suono era molto alta. Per cui, nel parlato, diventa molto importante parametrizzare l’inviluppo spettrale. Al momento, il sistema migliore è un metodo non lineare cosiddetto cepstrum e la sua variante mel-cepstrum. Tutte queste tecniche di analisi dei frames, hanno lo scopo di ricavare per ogni frame un vettore di caratteristiche. Ogni caratteristica del vettore, viene pesata in maniera diversa. Lo stato dell’arte per il trattamento di tale vettore, è l’MFCC(Mel Scale Cepstral Coefficient). Mel è una scala derivata da studi di psicoacustica che hanno sancito il fatto che lo studio del parlato può essere effettuato studiando lo spettro dopo averlo filtrato con una serie di filtri triangolari parzialmente sovrapposti che iniziano da una data frequenza e terminano ad una frequenza massima. La frequenza minima per il parlato è di 100Hz. Mel dice che l’uomo è sensibile non alla frequenza, ma al logaritmo della frequenza. Il filtro di Mel è applicato allo spettro di ogni frame. Una frequenza massima di 5000 Hz potrebbe aiutare ad eliminare gran parte del rumore. La frequenza massima dovrebbe essere inferiore, in ogni caso, alla frequenza di Nyquist (pari a metà della frequenza di campionamento).
Dove con Br si indicano le componenti spettrali appartenenti al filtro r-esimo ed N la dimensione della FFT. Quando parliamo di spettrogramma, in realtà stiamo trattando una rappresentazione in tre dimensioni. Se noi, di un segnale nel tempo facciamo la FFT, per ogni frame, allora possiamo creare una rappresentazione in cui, nelle ascisse porremo il tempo, nelle ordinate le frequenze. Preso un tempo ti nelle ascisse, e tracciando una riga verticale, su tale riga, potremo individuare varie zone di colore più o meno scuro. Se una parte è scura, significa che avrò molta energia per la frequenza che trovo nell’ordinata. In sostanza lo spettrogramma è una registrazione dell’andamento dell’energia dei vari frame, visualizzata per frequenza. Ovvero mi dice che, ad esempio, nel frame che incapsula il tempo ti, l’energia è molto più concentrata per una frequenza che non per l’altra. Proprio perché è riferita ai frames, si noti come lo spettrogramma ha un’andamento a striscie verticali. Avere più energia per una data frequenza, significa che nei momenti in cui il parlato aveva quella data frequenza, l’ampiezza del suono era molto alta. Per cui, nel parlato, diventa molto importante parametrizzare l’inviluppo spettrale. Al momento, il sistema migliore è un metodo non lineare cosiddetto cepstrum e la sua variante mel-cepstrum. Tutte queste tecniche di analisi dei frames, hanno lo scopo di ricavare per ogni frame un vettore di caratteristiche. Ogni caratteristica del vettore, viene pesata in maniera diversa. Lo stato dell’arte per il trattamento di tale vettore, è l’MFCC(Mel Scale Cepstral Coefficient). Mel è una scala derivata da studi di psicoacustica che hanno sancito il fatto che lo studio del parlato può essere effettuato studiando lo spettro dopo averlo filtrato con una serie di filtri triangolari parzialmente sovrapposti che iniziano da una data frequenza e terminano ad una frequenza massima. La frequenza minima per il parlato è di 100Hz. Mel dice che l’uomo è sensibile non alla frequenza, ma al logaritmo della frequenza. Il filtro di Mel è applicato allo spettro di ogni frame. Una frequenza massima di 5000 Hz potrebbe aiutare ad eliminare gran parte del rumore. La frequenza massima dovrebbe essere inferiore, in ogni caso, alla frequenza di Nyquist (pari a metà della frequenza di campionamento).
 ovvero il prodotto di due spettri, dove k è l’indice per le frequenze discrete. Poiché è difficile separare gli spettri di entrambi, allora il cepstrum usa gli algoritmi:
ovvero il prodotto di due spettri, dove k è l’indice per le frequenze discrete. Poiché è difficile separare gli spettri di entrambi, allora il cepstrum usa gli algoritmi: Se pensiamo a log |Y(k)| come ad un segnale nel tempo (anche se è in frequenza), è possibile distinguere due parti del segnale:
Se pensiamo a log |Y(k)| come ad un segnale nel tempo (anche se è in frequenza), è possibile distinguere due parti del segnale:
 Questa trasformata inversa, mi fornisce verso l’origine l’inviluppo spettrale, mentre in punti distanti compare l’eccitazione. In particolare nei punti in cui log |Y(k)| mostra la periodicità, allora la
Questa trasformata inversa, mi fornisce verso l’origine l’inviluppo spettrale, mentre in punti distanti compare l’eccitazione. In particolare nei punti in cui log |Y(k)| mostra la periodicità, allora la DTF mostrerà una riga. L’ascissa di DFT si chiama quefrency invece di frequency e ceps-trum stà a spec-trum. LA separazione quindi ha come effetto quello di separare l’inviluppo spettrale dall’eccitazione o sorgente. Tale separazione è quindi ottenuta moltiplicando il cepstrum per una finestra passa-basso nel dominio del cepstrum.  Quindi questo filtro passa basso serve per potere separare. Abbiamo che nc è una soglia opportuna. Scegliere questa soglia è importante. Per sceglierla bisogna ragionare sulle formanti. Per un uomo, la formante più bassa è pari a 270hz. Per una donna invece 310hz. Le oscillazioni dello spettro che corrispondono all’inviluppo non devono quindi avere componenti sopra la quefrency qp=3.7ms=1/270 Hz. Per suoni periodici bisogna scegliere nc < np, con np periodo in campioni.
Quindi questo filtro passa basso serve per potere separare. Abbiamo che nc è una soglia opportuna. Scegliere questa soglia è importante. Per sceglierla bisogna ragionare sulle formanti. Per un uomo, la formante più bassa è pari a 270hz. Per una donna invece 310hz. Le oscillazioni dello spettro che corrispondono all’inviluppo non devono quindi avere componenti sopra la quefrency qp=3.7ms=1/270 Hz. Per suoni periodici bisogna scegliere nc < np, con np periodo in campioni.
Per una frequenza di campionamento di 44khz, risulta np=44.1 x 3.7=163 campioni. Come soglia verrà però scelto un valore leggermente inferiore. In generale, le formanti, ovvero le frequenze
Nella disciplina dell’analisi dei suoni, il segnale, viene suddiviso in frame, ovvero porzioni di forma d’onda nel tempo. Assumendo che il segnale vari lentamente nel tempo, si può dire che, la scelta di un’opportuno frame di dimensione piccola, può comportare la possibilità di prelevare una unità di informazione, ovvero un’unità di suono. Nel parlato, tale valore è pari a 10ms, ovvero entro 10 ms, un essere umano può al massimo pronunciare un unico suono. Ciò significa che, per poter analizzare i suoni, ci interessa prelevare delle unità di informazione, ciascuna contenuta entro 10ms.
All’interno di un frame, si effettua un campionamento; infatti, è vero che, dentro un frame vi è un’unità di informazione, per cui basterebbe entro 10 ms prelevare un ampiezza, tanto il suono è uguale entro 10 ms, ma non ci si limita a ciò, si prende un vettore di parametri calcolati opportunamente sulla base del segnale contenuto entro il frame. Per potere ottenere il frame, si prende una forma d’onda quadrata di durata 10ms e si sposta nel tempo tale finestra (window). La window però non si sceglie quasi mai quadrata, ma smussata, in maniera tale da pesare maggiormente le caratteristiche della forma d’onda vicino al centro del frame, infatti si utilizza spesso la cosiddetta finestra di hamming, che ha la forma di una “piovra”.

La ragione per cui si scelgono window smussate, è perché con le forme quadrate, appena il filtro viene spostato, se si registrano parametri quali la somma dell’energia (come somma dei quadrati
dell’ampiezza di ogni campione).


trasformazione anche non lineare pesata dalla finestra w(n). Tale finestra può
essere la finestra di hamming (si parla anche di filtro FIR a risposta finita), che ci permette di ridurre il frame rate risparmiando i calcoli, oppure un filtro IIR (a risposta infinita):

Una cosa importante, per quanto concerne il riconoscimento del parlato, è la cosidetta Short-Time Average Energy, ovvero:

O meglio la short-time average magnitude, questo perché, la prima, ha il difetto di essere sensibile a grandi variazioni del segnale, essendo i campioni elevati al quadrato. Ricordo che s(i) trattasi dell’ampiezza del segnale nel punto i interno al frame che contiene N campioni.
 L’energia è importante nelle applicazioni vocali, in quanto l’energia varia molto come ampiezza nel tempo nel caso di suoni vocalizzati e non, come pure tra fonemi diversi; per cui viene permessa la segmentazione del parlato nei sistemi automatici di riconoscimento vocale, aiutando a determinare l’inizio e la fine delle parole isolate (ad esempio nel gms, se riesco a fare questo, allora evito di trasmettere le pause). Per avere informazioni sul contenuto spettrale della voce, si utilizza la trasformata di Fourier; però il alcuni casi, è sufficiente il ZCR (Zero Crossing Rate) per avere informazioni sul contenuto spettrale con richieste computazionali molto basse. Rappresenta il numero di volte per le quali il segnale passa per lo zero (o cambia segno) tra due campioni successivi. E’ possibile ricavare per segnali a banda stretta, la frequenza fondamentale F0 in questo modo:
L’energia è importante nelle applicazioni vocali, in quanto l’energia varia molto come ampiezza nel tempo nel caso di suoni vocalizzati e non, come pure tra fonemi diversi; per cui viene permessa la segmentazione del parlato nei sistemi automatici di riconoscimento vocale, aiutando a determinare l’inizio e la fine delle parole isolate (ad esempio nel gms, se riesco a fare questo, allora evito di trasmettere le pause). Per avere informazioni sul contenuto spettrale della voce, si utilizza la trasformata di Fourier; però il alcuni casi, è sufficiente il ZCR (Zero Crossing Rate) per avere informazioni sul contenuto spettrale con richieste computazionali molto basse. Rappresenta il numero di volte per le quali il segnale passa per lo zero (o cambia segno) tra due campioni successivi. E’ possibile ricavare per segnali a banda stretta, la frequenza fondamentale F0 in questo modo: Fs è la frequenza di campionamento del segnale e ZCR è espressa in zero crossing per campione. E’ possibile ottenere un valore di energia. Infatti, matematicamente, la ZCR equivale alla Q(n), per cui se sostituisco al posto del vettore T
Fs è la frequenza di campionamento del segnale e ZCR è espressa in zero crossing per campione. E’ possibile ottenere un valore di energia. Infatti, matematicamente, la ZCR equivale alla Q(n), per cui se sostituisco al posto del vettore T  … e scalo w(n) di un fattore 1/N, ottengo la seguente formula:
… e scalo w(n) di un fattore 1/N, ottengo la seguente formula:
 La ZCR ci aiuta a determinare segnali vocalizzati o meno. Infatti il modello vocale suggerisce che, al di sotto dei 3khz è concentrata l’energia della componente vocalizzata, mentre a frequenze più elevate abbiamo l’energia delle componenti non vocalizzate (unvoiced speed). Abbinando un analisi ZCR con la short-time average Energy, riesco ad individuare con precisione inizio e fine delle parole.Un’altra caratteristica del suono, è la short time autocorrelation, che è pari all’antitrasformata di
La ZCR ci aiuta a determinare segnali vocalizzati o meno. Infatti il modello vocale suggerisce che, al di sotto dei 3khz è concentrata l’energia della componente vocalizzata, mentre a frequenze più elevate abbiamo l’energia delle componenti non vocalizzate (unvoiced speed). Abbinando un analisi ZCR con la short-time average Energy, riesco ad individuare con precisione inizio e fine delle parole.Un’altra caratteristica del suono, è la short time autocorrelation, che è pari all’antitrasformata di  Fourier della densità spettrale di energia. In un certo senso l’autocorrelazione và a misurare la somiglianza tra un segnale ed il suo traslato (la formulaprecedente si riferisce ad un segnale discreto). Conserva le armoniche del segnale, l’ampiezza delle formanti e la loro frequenza. E’ inoltre caratterizzato da alcune caratteristiche importanti:
Fourier della densità spettrale di energia. In un certo senso l’autocorrelazione và a misurare la somiglianza tra un segnale ed il suo traslato (la formulaprecedente si riferisce ad un segnale discreto). Conserva le armoniche del segnale, l’ampiezza delle formanti e la loro frequenza. E’ inoltre caratterizzato da alcune caratteristiche importanti:- È una funzione pari;
- Per k=0 otteniamo il massimo;
- Per k=0 corrisponde l’energia del segnale o alla potenza media se i segnali
sono deterministici. - Riesco a stimare la periodicità del segnale perché anche l’autocorrelazione è
periodica con periodicità del segnale( cioè
f(k)=f(k+P)).

È ottenuta filtrando il segnale con delle finestre temporali. Perché è importante quest’ultima?Perché trova applicazione nell’estrazione dei pitch e nella discriminazione tra suono vocalizzato e non. Un’ulteriore alternativa a quest’ultima è la short time average magnitude difference function;
 Prendendo w(n) rettangolare di durata N, avrò:
Prendendo w(n) rettangolare di durata N, avrò:
Perché andare a ricercare la frequenza fondamentale? La frequenza fondamentale viene detta anche pitch e rappresenta per quanto concerne l’ambito del vocale, la frequenza fondamentale della vibrazione delle corde vocali. Posso utilizzare la short-time autocorrelation function per risalire a tale frequenza:
 Con Fs che è la frequenza di campionamento, kM è il campione m-simo a cui si rileva il primo massimo dopo quello per K=0. Quest’operazione viene effettuata dal cosiddetto stimatore di pitch che in genere attua 3 fasi:
Con Fs che è la frequenza di campionamento, kM è il campione m-simo a cui si rileva il primo massimo dopo quello per K=0. Quest’operazione viene effettuata dal cosiddetto stimatore di pitch che in genere attua 3 fasi:- filtraggio e semplificazione del segnale con la riduzione dei dati;
- estrazione del periodo;
- correzione di eventuali errori.
Inviluppo spettrale
L’inviluppo spettrale è molto importante nell’analisi del parlato. Infatti le zone della frequenza in cui si concentra l’energia si trovano in corrispondenza con le principali risonanze del tratto vocale. Queste risonanze sono molto importanti per riconoscere le vocali e le frequenze in cui si concentra l’energia vengono dette formanti. In genere gli strumenti musicali sono distinti da rispettivi inviluppi spettrali. Come si fa l’inviluppo? Si prende lo spettro in ampiezza e si selezionano i massimi. Tali massimi vengono congiunti con delle linee rette (attenzione, i massimi relativi della funzione!!) oppure sisuddivide l’asse delle frequenza in intervalli, ed in corrispondenza di essi(ascisse) si individuano le ampiezze e talune si collegano con dei segmenti. Come ottenere questi punti sulle ascisse? Ad esempio usando un banco di filtri passabanda equispaziati (banda costante) o distribuiti logaritmicamente sull’asse delle frequenze (filtri a Q costante).A livello computazionale, questi filtri possono essere implementati con la FFT, calcolando dapprima lo spettro in modulo, poi sommando i contributi di ciascun bin frequenziale pesato dallarisposta in frequenza dell’r-esimo filtro. Nel caso di passabanda rettangolari, si può calcolare l’energia Er(j) per il canale r-esimo del j-esimo frame con: Dove con Br si indicano le componenti spettrali appartenenti al filtro r-esimo ed N la dimensione della FFT. Quando parliamo di spettrogramma, in realtà stiamo trattando una rappresentazione in tre dimensioni. Se noi, di un segnale nel tempo facciamo la FFT, per ogni frame, allora possiamo creare una rappresentazione in cui, nelle ascisse porremo il tempo, nelle ordinate le frequenze. Preso un tempo ti nelle ascisse, e tracciando una riga verticale, su tale riga, potremo individuare varie zone di colore più o meno scuro. Se una parte è scura, significa che avrò molta energia per la frequenza che trovo nell’ordinata. In sostanza lo spettrogramma è una registrazione dell’andamento dell’energia dei vari frame, visualizzata per frequenza. Ovvero mi dice che, ad esempio, nel frame che incapsula il tempo ti, l’energia è molto più concentrata per una frequenza che non per l’altra. Proprio perché è riferita ai frames, si noti come lo spettrogramma ha un’andamento a striscie verticali. Avere più energia per una data frequenza, significa che nei momenti in cui il parlato aveva quella data frequenza, l’ampiezza del suono era molto alta. Per cui, nel parlato, diventa molto importante parametrizzare l’inviluppo spettrale. Al momento, il sistema migliore è un metodo non lineare cosiddetto cepstrum e la sua variante mel-cepstrum. Tutte queste tecniche di analisi dei frames, hanno lo scopo di ricavare per ogni frame un vettore di caratteristiche. Ogni caratteristica del vettore, viene pesata in maniera diversa. Lo stato dell’arte per il trattamento di tale vettore, è l’MFCC(Mel Scale Cepstral Coefficient). Mel è una scala derivata da studi di psicoacustica che hanno sancito il fatto che lo studio del parlato può essere effettuato studiando lo spettro dopo averlo filtrato con una serie di filtri triangolari parzialmente sovrapposti che iniziano da una data frequenza e terminano ad una frequenza massima. La frequenza minima per il parlato è di 100Hz. Mel dice che l’uomo è sensibile non alla frequenza, ma al logaritmo della frequenza. Il filtro di Mel è applicato allo spettro di ogni frame. Una frequenza massima di 5000 Hz potrebbe aiutare ad eliminare gran parte del rumore. La frequenza massima dovrebbe essere inferiore, in ogni caso, alla frequenza di Nyquist (pari a metà della frequenza di campionamento).
Dove con Br si indicano le componenti spettrali appartenenti al filtro r-esimo ed N la dimensione della FFT. Quando parliamo di spettrogramma, in realtà stiamo trattando una rappresentazione in tre dimensioni. Se noi, di un segnale nel tempo facciamo la FFT, per ogni frame, allora possiamo creare una rappresentazione in cui, nelle ascisse porremo il tempo, nelle ordinate le frequenze. Preso un tempo ti nelle ascisse, e tracciando una riga verticale, su tale riga, potremo individuare varie zone di colore più o meno scuro. Se una parte è scura, significa che avrò molta energia per la frequenza che trovo nell’ordinata. In sostanza lo spettrogramma è una registrazione dell’andamento dell’energia dei vari frame, visualizzata per frequenza. Ovvero mi dice che, ad esempio, nel frame che incapsula il tempo ti, l’energia è molto più concentrata per una frequenza che non per l’altra. Proprio perché è riferita ai frames, si noti come lo spettrogramma ha un’andamento a striscie verticali. Avere più energia per una data frequenza, significa che nei momenti in cui il parlato aveva quella data frequenza, l’ampiezza del suono era molto alta. Per cui, nel parlato, diventa molto importante parametrizzare l’inviluppo spettrale. Al momento, il sistema migliore è un metodo non lineare cosiddetto cepstrum e la sua variante mel-cepstrum. Tutte queste tecniche di analisi dei frames, hanno lo scopo di ricavare per ogni frame un vettore di caratteristiche. Ogni caratteristica del vettore, viene pesata in maniera diversa. Lo stato dell’arte per il trattamento di tale vettore, è l’MFCC(Mel Scale Cepstral Coefficient). Mel è una scala derivata da studi di psicoacustica che hanno sancito il fatto che lo studio del parlato può essere effettuato studiando lo spettro dopo averlo filtrato con una serie di filtri triangolari parzialmente sovrapposti che iniziano da una data frequenza e terminano ad una frequenza massima. La frequenza minima per il parlato è di 100Hz. Mel dice che l’uomo è sensibile non alla frequenza, ma al logaritmo della frequenza. Il filtro di Mel è applicato allo spettro di ogni frame. Una frequenza massima di 5000 Hz potrebbe aiutare ad eliminare gran parte del rumore. La frequenza massima dovrebbe essere inferiore, in ogni caso, alla frequenza di Nyquist (pari a metà della frequenza di campionamento).Ciò che stà alla base, è che la sorgente x(n) passa attraverso un filtro descritto dalla risposta all’impulso h(n) 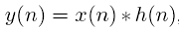
 ovvero il prodotto di due spettri, dove k è l’indice per le frequenze discrete. Poiché è difficile separare gli spettri di entrambi, allora il cepstrum usa gli algoritmi:
ovvero il prodotto di due spettri, dove k è l’indice per le frequenze discrete. Poiché è difficile separare gli spettri di entrambi, allora il cepstrum usa gli algoritmi: Se pensiamo a log |Y(k)| come ad un segnale nel tempo (anche se è in frequenza), è possibile distinguere due parti del segnale:
Se pensiamo a log |Y(k)| come ad un segnale nel tempo (anche se è in frequenza), è possibile distinguere due parti del segnale:- La parte a variazione veloce;
- la parte a variazione lenta.
 Questa trasformata inversa, mi fornisce verso l’origine l’inviluppo spettrale, mentre in punti distanti compare l’eccitazione. In particolare nei punti in cui log |Y(k)| mostra la periodicità, allora la
Questa trasformata inversa, mi fornisce verso l’origine l’inviluppo spettrale, mentre in punti distanti compare l’eccitazione. In particolare nei punti in cui log |Y(k)| mostra la periodicità, allora la Quindi questo filtro passa basso serve per potere separare. Abbiamo che nc è una soglia opportuna. Scegliere questa soglia è importante. Per sceglierla bisogna ragionare sulle formanti. Per un uomo, la formante più bassa è pari a 270hz. Per una donna invece 310hz. Le oscillazioni dello spettro che corrispondono all’inviluppo non devono quindi avere componenti sopra la quefrency qp=3.7ms=1/270 Hz. Per suoni periodici bisogna scegliere nc < np, con np periodo in campioni.
Quindi questo filtro passa basso serve per potere separare. Abbiamo che nc è una soglia opportuna. Scegliere questa soglia è importante. Per sceglierla bisogna ragionare sulle formanti. Per un uomo, la formante più bassa è pari a 270hz. Per una donna invece 310hz. Le oscillazioni dello spettro che corrispondono all’inviluppo non devono quindi avere componenti sopra la quefrency qp=3.7ms=1/270 Hz. Per suoni periodici bisogna scegliere nc < np, con np periodo in campioni.Per una frequenza di campionamento di 44khz, risulta np=44.1 x 3.7=163 campioni. Come soglia verrà però scelto un valore leggermente inferiore. In generale, le formanti, ovvero le frequenze
che corrispondono ai massimi dell’inviluppo spettrale sono molto utili in
quanto servono a differenziare le varie vocali. Poiché l’inviluppo spettrale ha
in ordinata l’energia, le formanti sono le frequenze sulle quali si concentra
la maggiore energia.







